
The web has changed a lot in the last few years so has web scraping. Web Scraping at scale is becoming increasingly difficult. Web applications are complex, dynamic and often apply various layers of p
By Victor Bolu @June, 23 2023
![the best web scraping tech stack for [2023]](https://webautomation.io/static/images/post_images/web_scraping_tech_stack.JPG)
Living in the age of information, the fastest data collection is in high demand, and web scraping tools and techniques are becoming popular day by day, especially when it comes to collecting large amounts of data from multiple different websites like social media platforms, news channels, financial institutes, and government official websites.
From a data engineer perspective, it is important to understand what is involved in scraping websites and what tools and techniques are best fit for given scenarios.
To choose the best-fit tools and techniques for web scraping, first, we need to understand the basic minimum procedure of web scraping.
Any web scraping job, takes three steps
Every web page is composed of multiple elements containing content (text, tables, images, videos). So exploring the structure of a web page and reaching a particular element with desired content is an important activity, and there are many tools available for this job.
Every good Browser provides dev tools to inspect webpages, google chrome dev tools are the best choice at this stage.
After exploring the structure of the website and selecting required elements to be scrapped, the next stage comes where we have to access and parse content from the website using automated programming scripts (python, js, PHP, java, etc).
Once we have parsed the response page provided by the server, now we need to store that data.
There are many tools and formats available to save data, SQL, CSV, JSON, SQLite and yml are mostly used ones. The nature of content coming from a website determines the storage format. For image data, we need to dump images in png or jpg format to drive storage. For text data we can use a simple txt format, if data is tabular then we can transform data and dump it into a database like SQL , SQLite or PostgreSQL or we can simply save data into csv or xlsx format.
For nested hierarchical content, we can dump data into json or yml formats.
After looking into the basic procedure of web scraping, now we will discuss the ultimate stack for web scraping available these days, and will see which stack provides us a better solution for our needs. I will talk about the technologies which are too important to ignore. You do not necessarily have to master all use them all, what is important is to be aware of all the options before you make a choice with your projects.
Firstly we need to understand how web scraping technology stacks are broken up and what pillars combine together to make up the full stack. We can safely break up the stack into these 5 pillars. Every Pillar is important and necessary for the others to work at scale.
The following picture shows the five pillars of every Web scraping Tech stack
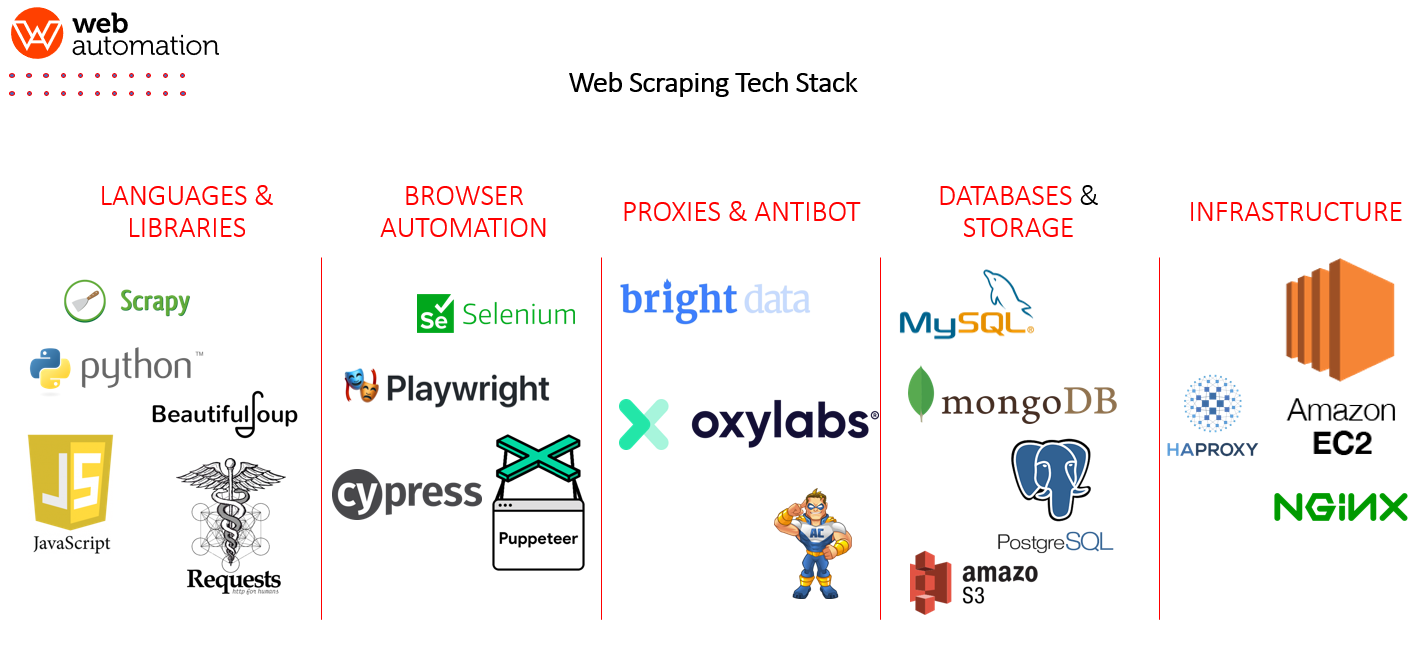
On a fundamental level, every programming language is capable of interacting with server and requesting for data, the complexity of web scraping varies from language to language,
Some languages provide very efficient frameworks and pipelines to make web scraping easier, python and javascript are top trending in web scraping these days.
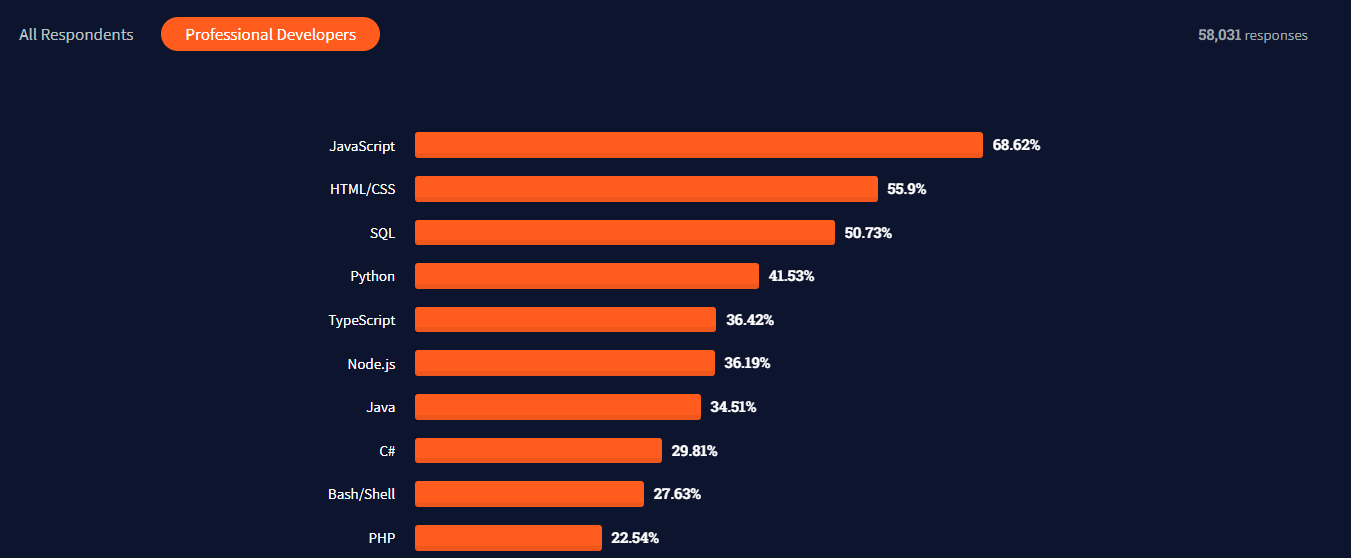
Most popular programming language 2021: Source Stackoverflow 2021 survey
Python as a scripting language is very famous these days, as it is very strong in data processing, its nature of loosely typed high-level language, rich set of web scraping frameworks (selenium, scrapy, beautiful soup etc) and strong n dimensional arrays provided by numpy and dataframes provided by pandas makes it robust programming language for scraping and processing data at larger scale.
If you are coming from a data driven ecosystem, then definitely python as a programming language for web scraping can be a better choice.
Request is an amazing library provided in python to interact and get responses from any website allowing you to make quick and easy HTTP calls. Beautifulsoup termed as bs4 is a famous web response parser available in python.
For simple static websites like Wikipedia, where the page is built of simple html content, requests and beautifulsoup is enough to scrape data. It is very easy to start without spending time in studying the documentation.
For content processing and transformation of data, no language is parallel to python, its strong numpy and pandas packages are enough to deal with any kind of tabular data and write ETL pipeline easily. And that is a reason why python is that much popular in web scraping.
For larger scale web scraping, python has a very famous framework called scrapy. It is a very strong framework as it handles every stage of web scraping very efficiently.
For handling crawling and fetching data, it provides spider class, and for data handling, it provides pipelines to develop customized solutions for data storage.
Scrapy contains very robust middleware, and every request coming from spider goes through middleware to data downloader, and similarly, data coming from downloader goes through middleware to pipelines so it could be stored efficiently.
As a programmer you need to write crawlers using spider class, rest of the work is managed by scrapy itself. To handle images or streaming data, you may need to change the configuration for pipelines and once that is done, scrapy handles files and folder hierarchy very efficiently.
Proxying IP, filtering unique urls, throttling requests to speed up web scraping are major features provided by scrapy framework.
If you are looking to scrape millions of images and text data from listing websites like eBay, scrapy is the best choice.
Using scrapy, you just need to write spiders as per the targeted website structure, the rest of the work is managed by scrapy.
We aim to make the process of extracting web data quick and efficient so you can focus your resources on what's truly important, using the data to achieve your business goals. In our marketplace, you can choose from hundreds of pre-defined extractors (PDEs) for the world's biggest websites. These pre-built data extractors turn almost any website into a spreadsheet or API with just a few clicks. The best part? We build and maintain them for you so the data is always in a structured form. .
For dynamically loaded websites, where data loads into a webpage on run time, we can’t use requests or scrapy framework to fetch that content directly, as to automate data loading we need to run javascript, which is not possible through html parsing scripts, so we need solution through which we could interact webpage and make a request by clicking on particular element or buttons on web page.
In python, we have a selenium library to interact with web pages on the browser side. It is a web testing automation tool, which can be used for scraping purposes easily.
By putting selenium in a loop, web scraping becomes much slower, as it has to load each web page into the browser and interact with elements manually. But the good part is, it works. For many websites where data is dynamically loaded, we don’t have another choice rather than selenium in python.
Before the release of node.js, javascript was a browser language only, but now It is everywhere.
Its asynchronous paradigm of functional programming makes it very efficient to interact with websites and fetch data as compared to other programming languages like python, java and c# etc.
Let's see what tools we have in JavaScript web scraping stack, and how these work.
Just like python, in node.js we have Request-Promise and CheerioJs modules, that we can use to make requests to web servers and parse response pages to get target information.
For static websites, where data is loaded in HTML page, we can use these two libraries to do scraping easily.
To process dynamically loaded websites and scrape data Puppeteer package is used. The asynchronous nature of node.js, make it a better choice to scrape data from websites that are dynamically loaded.
Puppeteer is easy to install and use for java script developers, as compared to selenium. Puppeteer is developed by google chrome dev team for automation, so it has more power to control google chrome as compared to selenium.
Few other roadblocks in web scraping
So far we have discussed various web scraping stacks, but there are some other roadblocks while scraping data, so whatever web scraping language and framework we use, we need to deal with these roadblocks.
With advancement in web development, web servers have become very smart these days. Detecting frequent requests from the same IP address and blocking it, is very common. Making a bundle of requests from the same ip address can result in blocking our system IP by web server, to avoid that we need to adopt proxying ip technique. There are many proxy services available.
Depending on the use case different providers and services are recommended i.e Datacenter, Residential, Mobile Proxies
To get a proxy server setup, you have two options
Captcha bypassing is another hurdle in web scraping. To bypass captcha many human labor-dependent web services are available.
DeathbyCaptcha, 2captcha, endcaptcha, captcha sniper and catcha tronix are top on the list.
Sometimes web servers put honey pot traps. These traps are actually web links exposed to crawling bots, but invisible to real web users. If the scraping bot is not well optimized then it can be detected and blocked by the server.
Once we have scraped data using our favorite web scraping tools, the data storage process is the final stage of web scraping. Choosing a good data storage solution is crucial these days, and it is very dependent on the nature of the data we are scraping.
For small scale data scraping, we can dump data into csv, xlsx , txt or json files.
But for large-scale data, where we need to make aloot of read and write requests, we can choose a good SQL server like Oracle SQL, MySQL, MS SQL.
If we are looking forward to server data to multiple applications across the network, then we must choose cloud storage services.
Google cloud service provides GCP storage, where we can write our data just like we do on our local machine. If our data is large in scale and in tabular format, then we can use SQL storage from google cloud or big query table.
AWS is famous for its tools and API to process data on large scale. For raw and unstructured data we can use the data lake provided by AWS, later we can use ETL tools like AWS Glue to reorganize data and athena to perform analytics on it.
AWS also provides SQL server that we can use to dump tabular data.
There are many use cases where we just want to save the data in storage for archive purposes. In this case, the data could grow rapidly and become expensive to store. Amazon S3 in this case becomes easier and cheaper
Most popular databases 2021: Stack overflow survery
In our modern times, so many new and unconventional databases are becoming very popular but for every data engineer when database comes to mind we will refer to relational databases and SQL
The big Four SQL Relational database remain - Oracle, MySQL, Microsoft SQL Server and PostgreSQL
Although MySQL is the most popular database choice, you should also note that MySQL has some limits so if you are dealing with very big data web scraping projects this might not be a good choice
Using MongoDB essentially eradicates the need to normalize the data to accommodate the database, you can store non-uniform and no relational data without many performance problems. Also, MongoDB can accommodate very large amounts of data. For the web scraping use case MongoDB cloud does make it easy to store scraped data without setting up a local database
Web scraping is very compute-heavy and requires a lot of resources when scraping at scale. A scalable server infrastructure is important to ensure you do not run out of resources mid-way through the scraping process.
One of the most popularly used and cost-effective solutions is AWS-EC2 by Amazon. It helps you run code on a Linux or a Windows server
For managing traffic and proxies popular tools include HAproxy and NGINX, which are free open source load balancing and HTTP server and reverse proxy
Web scraping skill is high in demand these days and choosing a proper web scraping stack makes the job easier especially when you are trying to build a scalable project
Any programming language is capable of doing web scraping, but python and javascript are top trending currently.
Web scraping with python becomes easy as it provides robust libs and framework feasible for each stage of scraping.
Scrapy is a complete solution for web scraping, as it handles every strop of web scraping easily. Its customized interface for writing crawler, robust middleware, and automated requests optimization makes a programmer's job easy.
Async nature of node.js makes web scraping easier especially when it comes to scraping dynamically loaded web scraping.
We aim to make the process of extracting web data quick and efficient so you can focus your resources on what's truly important, using the data to achieve your business goals. In our marketplace, you can choose from hundreds of pre-defined extractors (PDEs) for the world's biggest websites. These pre-built data extractors turn almost any website into a spreadsheet or API with just a few clicks. The best part? We build and maintain them for you so the data is always in a structured form. .
RECENT POSTS
RELATED POSTS

How To Grow Your Business With Web Scraping
@13/06/2023
CATEGORIES
follow us on



 Linkedin
Linkedin